NELS - Never-Ending Learner of Sounds
I Crawl, I Hear, I Learn
Abstract
Sounds are captured in recordings and shared on the Internet on a minute-by-minute basis. These recordings, which are predominantly videos, constitute the largest archive of sounds we know. However, most of these audios are unlabeled in terms of their content, requiring methods for automatic content analysis, which poses unique challenges when done on a large-scale. Therefore, we propose the Never-Ending Learner of Sounds (NELS), a framework for large-scale learning of sounds and its associated knowledge. Currently, NELS has a vocabulary of over 600 sounds drawn from four different datasets and has processed over 4 million segments of YouTube videos. The never-ending architecture is inspired by the Never-Ending Language Learner (NELL) and the Never-Ending Image Learner (NEIL).
Flow Diagram
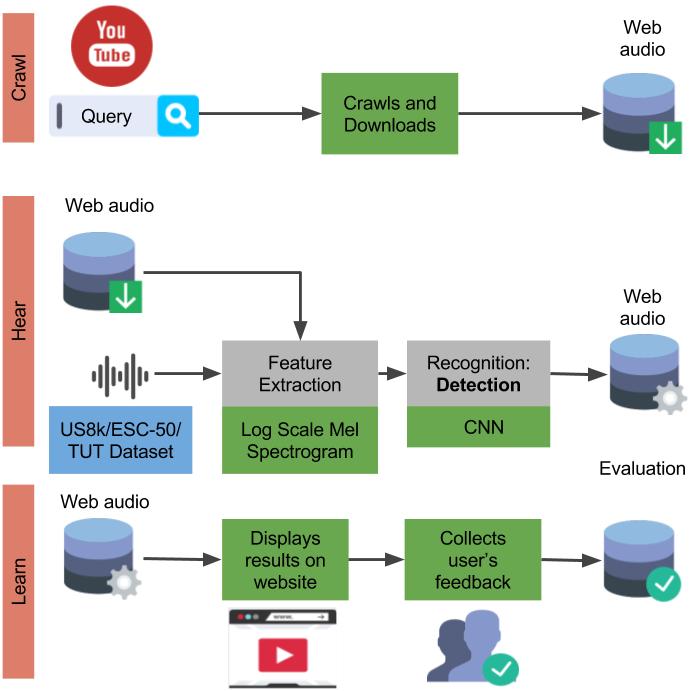
The framework consists of three modules Crawl, Hear & Learn and Website, illustrated in the Figure. Currently, in Crawl, audio and its associated metadata from YouTube videos is crawled using search queries corresponding to the class labels ($<$sound event label$>$ sound) drawn from four datasets. In Hear & Learn, the datasets are used to train multi-class classifiers, which are then run on segments of the crawled videos. Classifier's predictions and metadata are used to index the segments. Lastly, the Website module allows users to search for the indexed audio using a text or audio query, then, the results are displayed allowing human feedback to evaluate quality. The feedback is also used to index the segments.
